“The Art and Science of AI Model Training: A Comprehensive Guide
Artikel Terkait The Art and Science of AI Model Training: A Comprehensive Guide
- Progressive Web Apps: The Future Of Web Experiences
- Diving Deep Into Android Development: A Comprehensive Guide
- The Rise Of The Digital Assistant: From Science Fiction To Everyday Reality
- The Rise Of The Intelligent Assistant: Navigating The World With AI By Your Side
- Navigating The Ethical Labyrinth: AI Governance In The 21st Century
Table of Content
Video tentang The Art and Science of AI Model Training: A Comprehensive Guide
The Art and Science of AI Model Training: A Comprehensive Guide

Artificial intelligence (AI) is rapidly transforming industries, powering everything from personalized recommendations to self-driving cars. At the heart of this transformation lies AI model training, the process of teaching a machine learning algorithm to perform a specific task. This article delves into the intricacies of AI model training, exploring the key steps, challenges, and best practices involved in creating effective and reliable AI models.
What is AI Model Training?
At its core, AI model training is about feeding data to a machine learning algorithm and allowing it to learn patterns and relationships within that data. This learning process involves adjusting the algorithm’s internal parameters to minimize errors and improve its ability to make accurate predictions or classifications. Think of it like teaching a child to recognize a cat. You show the child many pictures of cats, pointing out their features. Eventually, the child learns to identify a cat even if it’s a different breed or in a different pose. AI model training operates on a similar principle, albeit with far more complex algorithms and datasets.
The Stages of AI Model Training: A Step-by-Step Breakdown
The process of AI model training can be broken down into several key stages:
1. Data Collection and Preparation:
- Data Acquisition: The first and arguably most crucial step is gathering relevant data. This data could come from various sources, including databases, APIs, web scraping, sensors, and human-generated content. The type of data required depends entirely on the task the AI model is intended to perform. For example, training a model to recognize different types of flowers requires a dataset of images labeled with the corresponding flower names.
- Data Cleaning: Raw data is often messy and incomplete. This stage involves identifying and correcting errors, handling missing values, removing duplicates, and addressing inconsistencies. Techniques like imputation (filling in missing values), outlier detection, and data normalization are commonly employed. Clean data ensures the model learns from accurate information and avoids biases.
- Data Transformation: Data often needs to be transformed into a format suitable for the chosen machine learning algorithm. This might involve converting categorical data into numerical representations (e.g., using one-hot encoding), scaling numerical data to a specific range, or applying feature engineering techniques to create new features from existing ones. Feature engineering is particularly important for improving model performance by highlighting relevant patterns in the data.
- Data Splitting: The prepared data is typically split into three subsets:
- Training Set: Used to train the model. The algorithm learns from this data and adjusts its internal parameters.
- Validation Set: Used to evaluate the model’s performance during training and tune hyperparameters. This helps prevent overfitting (where the model performs well on the training data but poorly on unseen data).
- Test Set: Used to evaluate the final trained model’s performance on completely unseen data. This provides an unbiased estimate of the model’s generalization ability. A common split is 70% for training, 15% for validation, and 15% for testing.

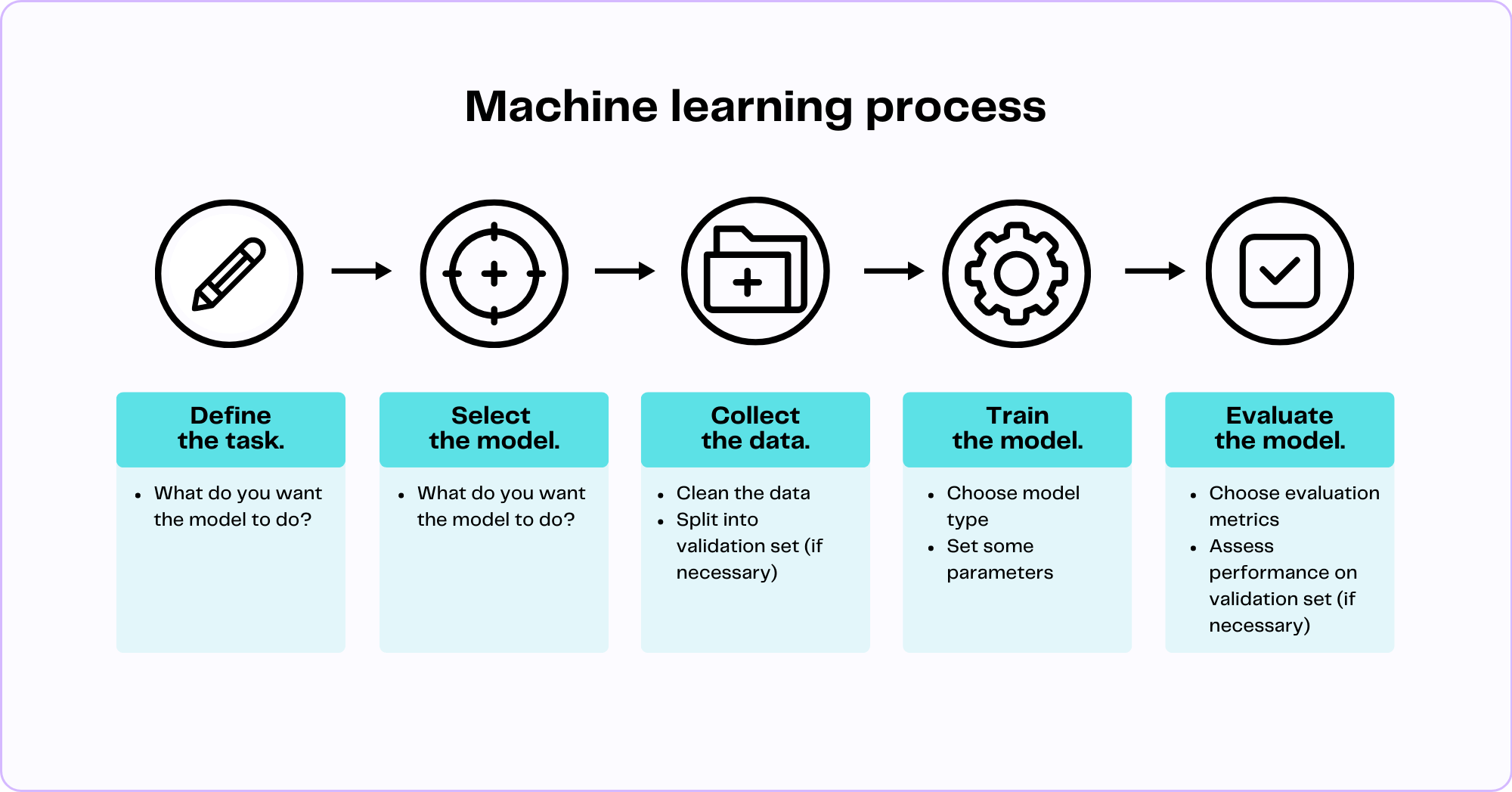
2. Model Selection:
- Choosing the Right Algorithm: Selecting the appropriate machine learning algorithm is crucial for achieving optimal performance. The choice depends on the type of problem (e.g., classification, regression, clustering), the characteristics of the data, and the desired performance metrics. Some popular algorithms include:

- Linear Regression: For predicting continuous values.
- Logistic Regression: For binary classification problems.
- Decision Trees: For both classification and regression.
- Support Vector Machines (SVMs): For classification and regression, particularly effective in high-dimensional spaces.
- Neural Networks: Powerful algorithms for complex tasks like image recognition and natural language processing. Different types of neural networks exist, including Convolutional Neural Networks (CNNs) for image processing and Recurrent Neural Networks (RNNs) for sequential data.
- Ensemble Methods: Combine multiple models to improve accuracy and robustness (e.g., Random Forests, Gradient Boosting Machines).
- Model Architecture (for Neural Networks): For neural networks, selecting the appropriate architecture is critical. This involves determining the number of layers, the number of neurons in each layer, and the types of activation functions to use. Experimentation and knowledge of the problem domain are often required to find the optimal architecture.
3. Model Training:
- Feeding the Data: The training data is fed to the chosen algorithm.
- Parameter Adjustment: The algorithm iteratively adjusts its internal parameters to minimize a predefined loss function. The loss function measures the difference between the model’s predictions and the actual values in the training data.
- Optimization Algorithms: Optimization algorithms like Gradient Descent are used to find the parameter values that minimize the loss function. These algorithms iteratively update the parameters based on the gradient of the loss function.
- Epochs and Batch Size: Training is typically performed over multiple epochs, where each epoch represents one complete pass through the training data. The data is often processed in smaller batches to improve efficiency and prevent memory issues. The batch size determines the number of data points used in each iteration.
- Regularization Techniques: Regularization techniques, such as L1 and L2 regularization, are often used to prevent overfitting. These techniques add a penalty term to the loss function that discourages the model from learning overly complex patterns.
4. Model Evaluation and Tuning:
- Evaluation Metrics: The model’s performance is evaluated using appropriate metrics, such as accuracy, precision, recall, F1-score, and area under the ROC curve (AUC) for classification problems, and mean squared error (MSE) and R-squared for regression problems.
- Hyperparameter Tuning: Hyperparameters are parameters that are not learned from the data but are set before training. Examples include the learning rate, the number of hidden layers in a neural network, and the regularization strength. Hyperparameter tuning involves finding the optimal values for these parameters to maximize the model’s performance on the validation set. Techniques like grid search, random search, and Bayesian optimization are commonly used.
- Overfitting and Underfitting: It’s crucial to monitor for overfitting and underfitting. Overfitting occurs when the model learns the training data too well and performs poorly on unseen data. Underfitting occurs when the model is too simple and cannot capture the underlying patterns in the data. Techniques like cross-validation and regularization can help mitigate these issues.
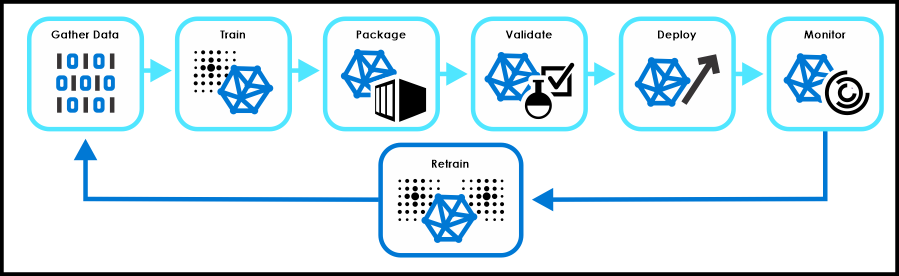
5. Model Deployment and Monitoring:
- Deployment: Once the model has been trained and evaluated, it can be deployed to a production environment to make predictions on new data.
- Monitoring: It’s essential to continuously monitor the model’s performance after deployment. Model performance can degrade over time due to changes in the data distribution (data drift). Monitoring helps identify when the model needs to be retrained or updated.
Challenges in AI Model Training:
- Data Quality: Poor data quality can significantly impact model performance.
- Computational Resources: Training complex models, especially deep learning models, can require significant computational resources, including powerful GPUs and large amounts of memory.
- Overfitting: Preventing overfitting is a common challenge, requiring careful selection of hyperparameters and regularization techniques.
- Interpretability: Some models, particularly deep learning models, can be difficult to interpret, making it challenging to understand why they make certain predictions.
- Bias: AI models can inherit biases from the data they are trained on, leading to unfair or discriminatory outcomes.
- Data Privacy: Protecting the privacy of sensitive data used for training is a critical concern.
Best Practices for AI Model Training:
- Start with a Clear Goal: Define the problem you are trying to solve and the desired outcome.
- Gather High-Quality Data: Invest time and effort in collecting and preparing high-quality data.
- Choose the Right Algorithm: Select an algorithm that is appropriate for the task and the data.
- Tune Hyperparameters Carefully: Experiment with different hyperparameter values to optimize performance.
- Monitor for Overfitting: Use validation sets and regularization techniques to prevent overfitting.
- Evaluate Model Performance Thoroughly: Use appropriate evaluation metrics to assess the model’s performance.
- Consider Interpretability: Choose models that are interpretable, especially in applications where explainability is important.
- Address Bias: Identify and mitigate potential biases in the data and the model.
- Prioritize Data Privacy: Implement appropriate measures to protect data privacy.
- Document Everything: Keep detailed records of the data, the model, the training process, and the evaluation results.
FAQ:
What is the difference between machine learning and deep learning?
Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers (hence "deep") to analyze data. Deep learning excels at complex tasks like image recognition and natural language processing, while machine learning encompasses a broader range of algorithms.
How much data do I need to train an AI model?
The amount of data required depends on the complexity of the problem and the algorithm used. Simpler models may require less data, while complex models like deep neural networks often require large datasets. A general rule of thumb is that more data is better, but the quality of the data is equally important.
What is transfer learning?
Transfer learning is a technique where a model trained on one task is reused as a starting point for a model on a different but related task. This can significantly reduce the amount of data and training time required.
What tools are used for AI model training?
Several tools are available for AI model training, including:
- Programming Languages: Python, R
- Machine Learning Libraries: TensorFlow, PyTorch, scikit-learn, Keras
- Cloud Platforms: AWS SageMaker, Google Cloud AI Platform, Microsoft Azure Machine Learning
How do I know if my model is good enough?
The definition of "good enough" depends on the specific application. You need to define clear performance metrics and set a target performance level. It’s also important to consider the trade-offs between different performance metrics (e.g., accuracy vs. precision).
Conclusion:
AI model training is a complex and iterative process that requires careful attention to detail. By understanding the key stages, challenges, and best practices, you can build effective and reliable AI models that solve real-world problems. As AI continues to evolve, the importance of skilled AI model trainers will only continue to grow. The journey of mastering AI model training is a continuous learning experience, demanding both technical expertise and a deep understanding of the problem domain. Embrace the challenges, experiment with different approaches, and contribute to the ever-expanding world of artificial intelligence.