“Federated Learning: Training AI Without Sharing Data
Artikel Terkait Federated Learning: Training AI Without Sharing Data
- The Rise Of The Intelligent Assistant: Navigating The World With AI By Your Side
- Navigating The Ethical Labyrinth: AI Governance In The 21st Century
- Unveiling The Black Box: A Deep Dive Into Explainable AI (XAI)
- The Rise Of The Conversational Machines: A Deep Dive Into AI Chatbots
- Diving Deep Into IOS Development: A Comprehensive Guide
Table of Content
Video tentang Federated Learning: Training AI Without Sharing Data
Federated Learning: Training AI Without Sharing Data

In today’s data-driven world, artificial intelligence (AI) and machine learning (ML) are transforming industries from healthcare to finance. However, training robust and accurate AI models often requires massive datasets, raising concerns about data privacy, security, and access. Federated Learning (FL) emerges as a powerful solution to these challenges, enabling collaborative model training across decentralized devices or servers while keeping data localized.
What is Federated Learning?
Federated Learning is a distributed machine learning approach that trains a shared global model across multiple decentralized devices or servers (referred to as "clients") without directly exchanging their data. Instead, each client trains a local model on its own data, and then only model updates, such as gradients or parameters, are shared with a central server. The server aggregates these updates to create a refined global model, which is then distributed back to the clients for further local training. This iterative process continues until the global model converges to a desired level of accuracy.
Think of it as a group of chefs each using their own unique ingredients (data) to develop a specific dish (local model). They then share only the recipe adjustments they made (model updates) with a head chef. The head chef combines these adjustments to create a master recipe (global model) and shares it back with everyone. This process repeats until the master recipe is perfected, without anyone ever revealing their original ingredients.
Key Components of Federated Learning:
- Clients: These are the decentralized devices or servers holding the local data. They can be anything from smartphones and IoT devices to hospitals and banks.
- Local Data: The data residing on each client is unique and remains on the client device. It’s crucial for training the local model.
- Local Model: Each client trains a machine learning model on its local data. This model is initialized with the current global model.
- Model Updates: After local training, clients send only the model updates (e.g., gradients, parameters) to the central server.
- Central Server: The central server aggregates the model updates received from the clients to improve the global model.
- Global Model: The shared model that is trained collaboratively across all clients. It’s periodically updated and distributed back to the clients.
- Aggregation Algorithm: The method used by the central server to combine the model updates from the clients. Common algorithms include Federated Averaging (FedAvg) and Federated Stochastic Gradient Descent (FedSGD).
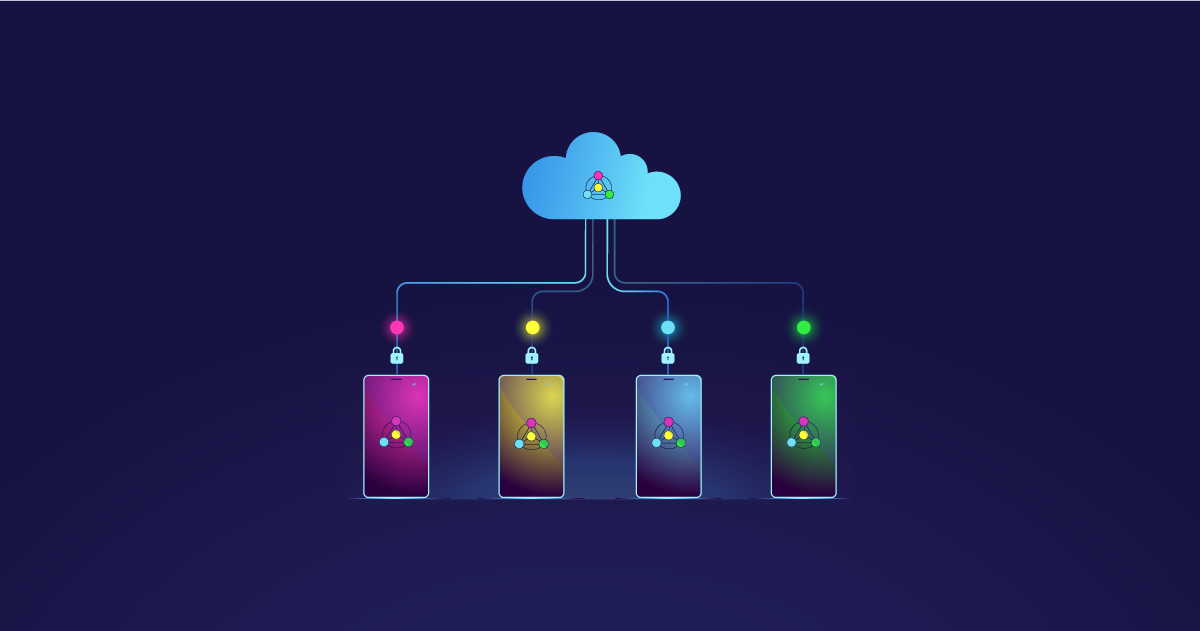
The Federated Learning Process:
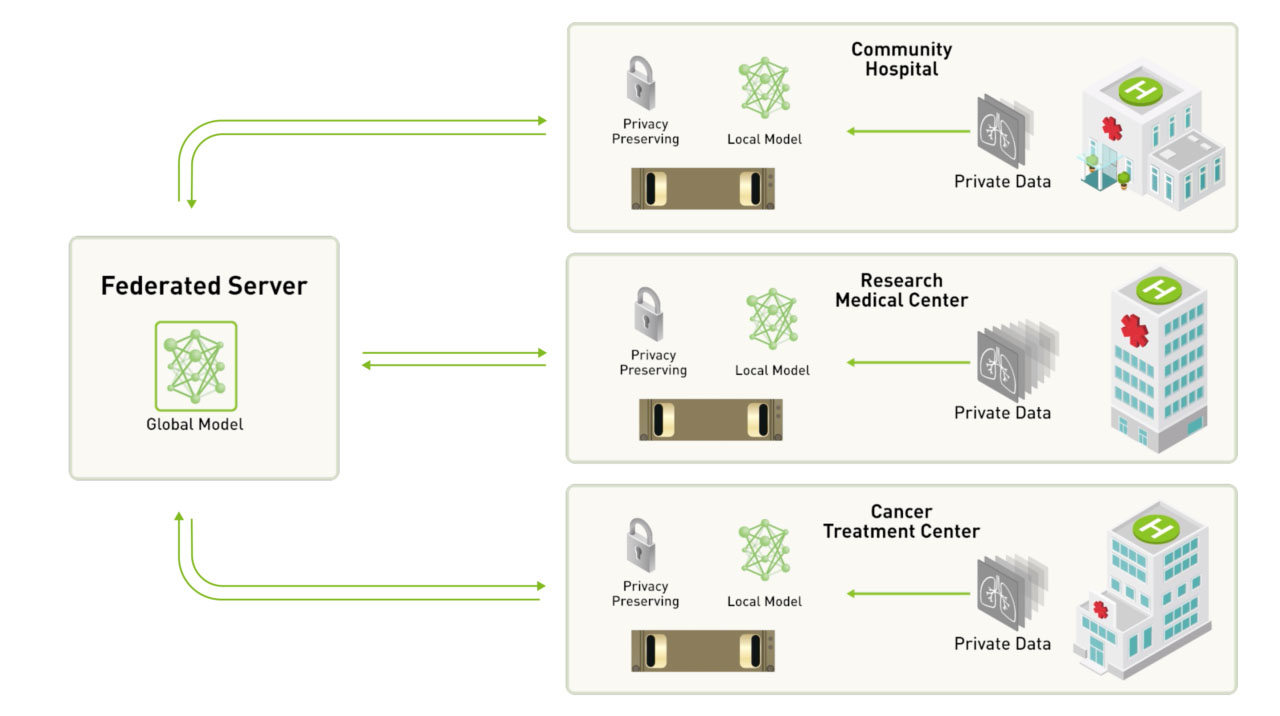
- Initialization: The central server initializes a global model and distributes it to a subset of clients.
- Local Training: Each selected client trains the global model on its local data for a specific number of iterations.
- Model Update Transmission: After local training, each client sends its model updates (e.g., gradients) to the central server.
- Aggregation: The central server aggregates the model updates received from the clients using a chosen aggregation algorithm (e.g., FedAvg). This results in an updated global model.
- Global Model Update: The updated global model is distributed back to the clients for the next round of local training.
- Iteration: Steps 2-5 are repeated until the global model converges to a desired level of accuracy or a predefined number of rounds are completed.

Benefits of Federated Learning:
- Data Privacy: FL protects data privacy by keeping data localized on the client devices. Only model updates, which are less sensitive than raw data, are shared.
- Data Security: By eliminating the need to transfer data to a central location, FL reduces the risk of data breaches and security vulnerabilities.
- Reduced Communication Costs: FL minimizes the amount of data transmitted over the network, leading to reduced communication costs, especially in resource-constrained environments.
- Access to Distributed Data: FL enables training models on data that is geographically distributed or inaccessible due to regulatory restrictions.
- Improved Model Generalization: Training on diverse datasets across multiple clients can lead to more robust and generalizable models.
- Compliance with Data Regulations: FL helps organizations comply with data privacy regulations like GDPR and CCPA, which restrict the transfer and storage of personal data.
Challenges of Federated Learning:
- Communication Constraints: FL relies on communication between clients and the central server, which can be a bottleneck, especially with limited bandwidth or unreliable network connections.
- System Heterogeneity: Clients in a federated learning system can have varying computing capabilities, storage capacity, and network connectivity. This heterogeneity can impact the training process.
- Statistical Heterogeneity: The data distribution across clients can be highly non-identical and independent (non-IID). This statistical heterogeneity can lead to biased models and slower convergence.
- Client Selection: Choosing the right subset of clients for each training round is crucial for efficient and effective training.
- Security and Privacy Attacks: FL is not immune to security and privacy attacks. Malicious clients can inject poisoned data or infer sensitive information from model updates.
- Byzantine Fault Tolerance: FL needs to be robust to Byzantine faults, where clients can exhibit arbitrary and malicious behavior.
- Aggregation Algorithm Design: Designing aggregation algorithms that are robust to heterogeneity, communication constraints, and security threats is a challenging task.
Addressing the Challenges:
Researchers are actively working on addressing the challenges of federated learning. Some of the approaches include:
- Communication-Efficient Techniques: Techniques like model compression, quantization, and sparsification can reduce the communication overhead.
- Adaptive Learning Rates: Adjusting learning rates based on client-specific data characteristics can improve convergence in heterogeneous environments.
- Data Augmentation: Techniques like Generative Adversarial Networks (GANs) can be used to augment local datasets and mitigate the impact of statistical heterogeneity.
- Secure Aggregation: Cryptographic techniques like secure multi-party computation (MPC) can be used to protect model updates during aggregation.
- Differential Privacy: Adding noise to model updates can provide differential privacy guarantees, protecting against privacy attacks.
- Client Selection Strategies: Developing intelligent client selection strategies that prioritize clients with high-quality data or reliable network connections.
Applications of Federated Learning:
Federated Learning has a wide range of applications across various industries:
- Healthcare: Training models for disease diagnosis, personalized medicine, and drug discovery using patient data from multiple hospitals without sharing sensitive information.
- Finance: Detecting fraud, predicting credit risk, and personalizing financial services using transaction data from multiple banks while preserving customer privacy.
- Telecommunications: Optimizing network performance, improving user experience, and developing new services using data from mobile devices.
- Retail: Personalizing recommendations, optimizing inventory management, and improving customer service using customer data from multiple stores.
- Autonomous Driving: Training models for autonomous vehicles using data from multiple vehicles without sharing driving data.
- Internet of Things (IoT): Developing smart home applications, optimizing energy consumption, and improving industrial automation using data from IoT devices.
Future Trends in Federated Learning:
- Personalized Federated Learning: Tailoring the global model to individual client needs and preferences.
- Decentralized Federated Learning: Eliminating the central server and enabling peer-to-peer model aggregation.
- Federated Transfer Learning: Leveraging pre-trained models and transferring knowledge across different domains.
- Federated Reinforcement Learning: Training reinforcement learning agents in a distributed and privacy-preserving manner.
- Integration with Blockchain: Using blockchain technology to ensure data integrity and transparency in federated learning systems.
Federated Learning FAQ:
Q: Is Federated Learning completely secure?
A: While FL significantly enhances privacy compared to traditional centralized learning, it’s not entirely immune to attacks. Techniques like differential privacy and secure aggregation are employed to further strengthen security.
Q: What happens if a client drops out during training?
A: Federated Learning algorithms are designed to be robust to client dropouts. The central server can continue training with the updates received from the remaining clients. Client selection strategies can also prioritize clients with reliable network connections.
Q: How does Federated Learning handle biased data?
A: Statistical heterogeneity (non-IID data) is a major challenge in FL. Techniques like data augmentation, adaptive learning rates, and personalized federated learning can help mitigate the impact of biased data.
Q: Can I use Federated Learning with any machine learning model?
A: In theory, yes. However, some models are more amenable to FL than others. Models with a large number of parameters may require more communication overhead.
Q: What programming languages and frameworks are used for Federated Learning?
A: Popular frameworks include TensorFlow Federated (TFF), PySyft, and Flower. Python is the most commonly used programming language.
Q: How do I choose the right aggregation algorithm for my Federated Learning task?
A: The choice of aggregation algorithm depends on the specific characteristics of the data, the communication constraints, and the security requirements. FedAvg is a common starting point, but other algorithms may be more suitable for specific scenarios.
Q: What are the hardware requirements for Federated Learning?
A: The hardware requirements depend on the complexity of the model and the size of the local datasets. Clients need sufficient computing power and storage capacity to train the local model.
Conclusion:
Federated Learning offers a promising approach to training AI models while preserving data privacy and security. While challenges remain, ongoing research and development are paving the way for wider adoption of FL across various industries. As data privacy regulations become more stringent and the demand for AI continues to grow, Federated Learning is poised to play an increasingly important role in shaping the future of machine learning. By enabling collaborative learning without compromising data ownership, FL empowers organizations to unlock the full potential of their data and build more robust, generalizable, and ethical AI systems. The ability to learn from diverse, decentralized datasets while protecting sensitive information makes Federated Learning a critical technology for the next generation of AI.
